
개발자 끄적끄적
보조 저장장치의 관리 본문
<파일(File)>
- 사용자나 응용 프로그램의 관점
- 정보를 저장하고 관리하는 논리적인 단위
- 저장 형식과 내용은 프로그래머에 의해 결정
- 컴퓨터 시스템의 관점
- 정보를 저장하는 최소 단위의 컨테이너
- 바이트의 나열
- OS에 의해 관리/조작됨
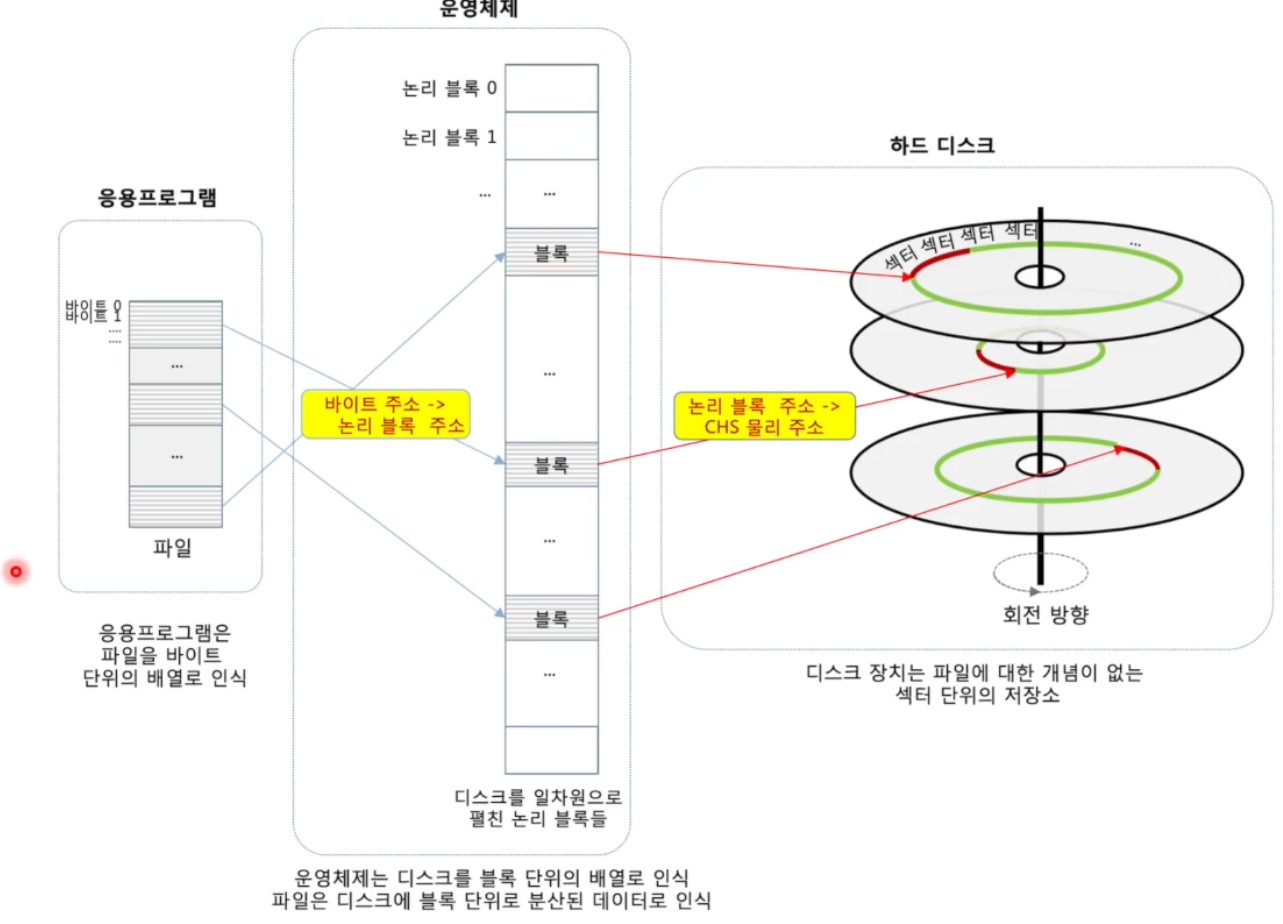
<파일 입출력 주소>
- 응용 프로그램은 파일 내 바이트 주소 사용
- 파일 내 바이트 위치(offset)
- 운영체제는 논리 블록 주소(LBA, logical block addr.) 사용
- 저장 매체를 1차원의 연속된 데이터 블록들로 봄
- 저장 매체의 종류와 무관
- 파일을 블록 크기로 분할하고, 디스크에 분산 저장
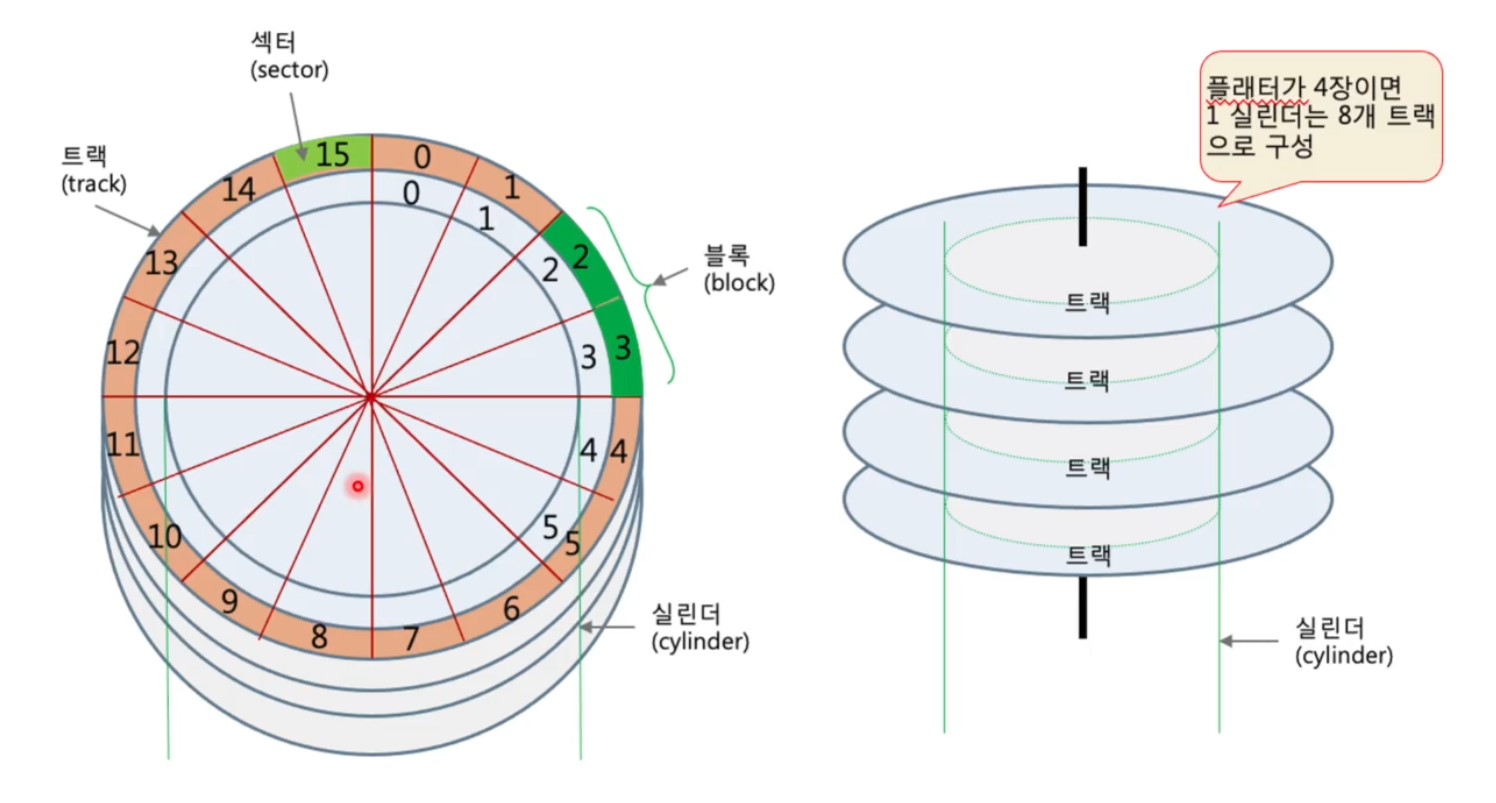
- 디스크 장치는 디스크 물리 주소 사용
- 디스크의 섹터 위치를 나타내는 주소
- CHS 물리주소 = (실린더번호, 헤드번호, 섹터번호)
- 디스크 장치의 펌웨어가 LBA를 CHS로 변환
<하드 디스크 드라이브(HHD)의 구조>
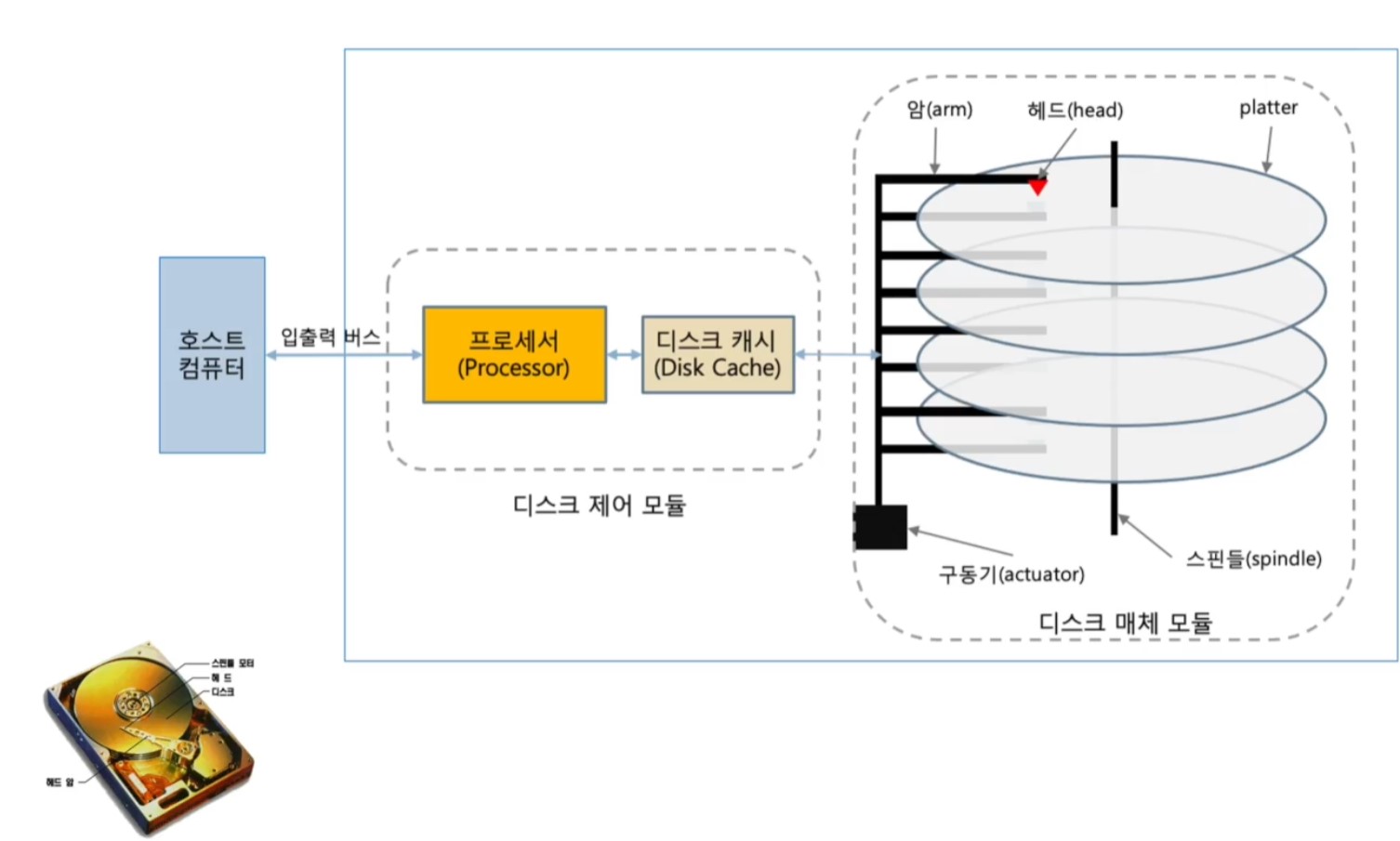
<자기 디스크(Magnetic Disk)구조>
<주소 계층화의 의미>
- 각 계층의 독립적 구현이 용이
- 응용 프로그램 개발 가능
- 파일을 바이트 나열로 가정하고 입출력 프로그래밍
- OS 종류나 저장장치의 종류와 무관하게 파일 입출력 가능
- 운영체제 개발
- 저장 매체의 종류와 무관하게 OS 구현 가능
- 그저 바이트 주소를 LBA로 바꿈으로 장치 독립적으로 처리
- 저장 장치 개발
- app, OS와 무관하게 저장 장치 개발
<계층화와 접근 주소의 변환>
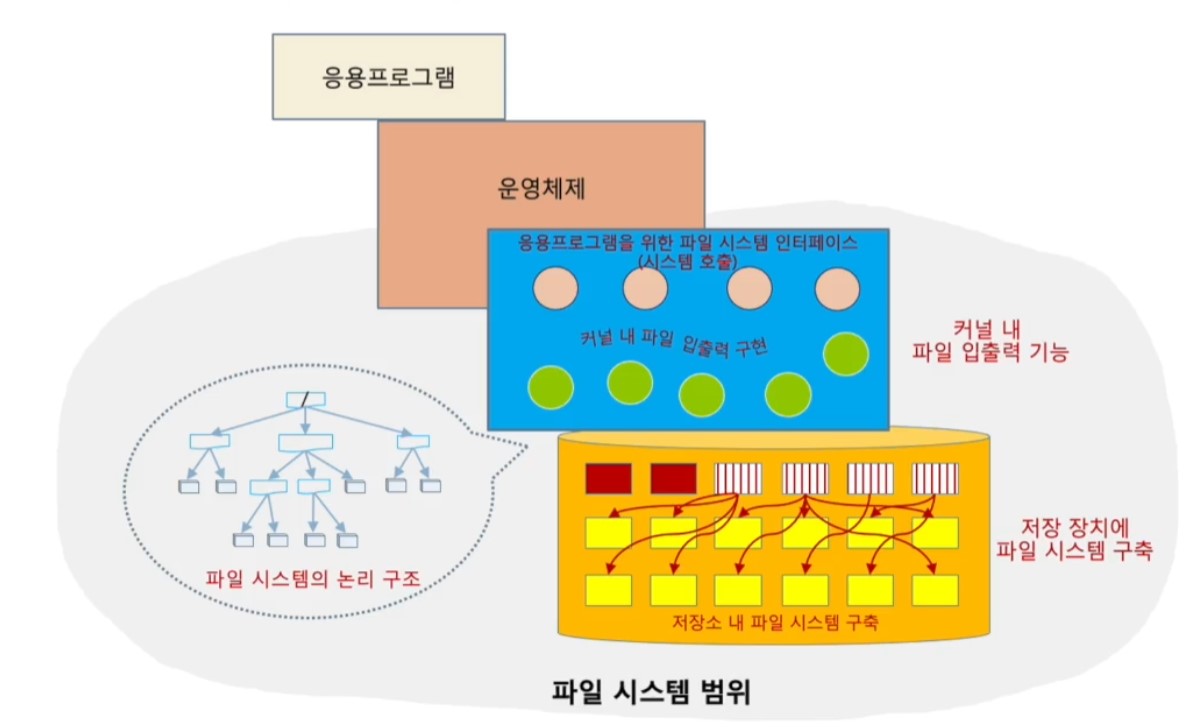
<파일 시스템(File System)>
- 저장 매체에 파일을 생성해 저장하고 읽고 쓰는 OS의 기능에 대한 통칭
<파일 시스템의 구성>
- 파일 시스템의 논리 구조
- 디렉터리 파일로 이루어지는 계층적인 트리 구조
- 저장소에 구축되는 파일 시스템
- 사용 블록, 빈 블록에 대한 정보 유지
- 커널 내 파일 입출력 기능 구현
- 파일 생성, 열기, 읽기, 쓰기, 닫기, 삭제
- 파일 메타 정보 읽기/변경
- app을 위한 시스템 호출 제공
- open(), close(), read(), write(), seek() 등
<파일 읽기를 통한 입출력 개요>
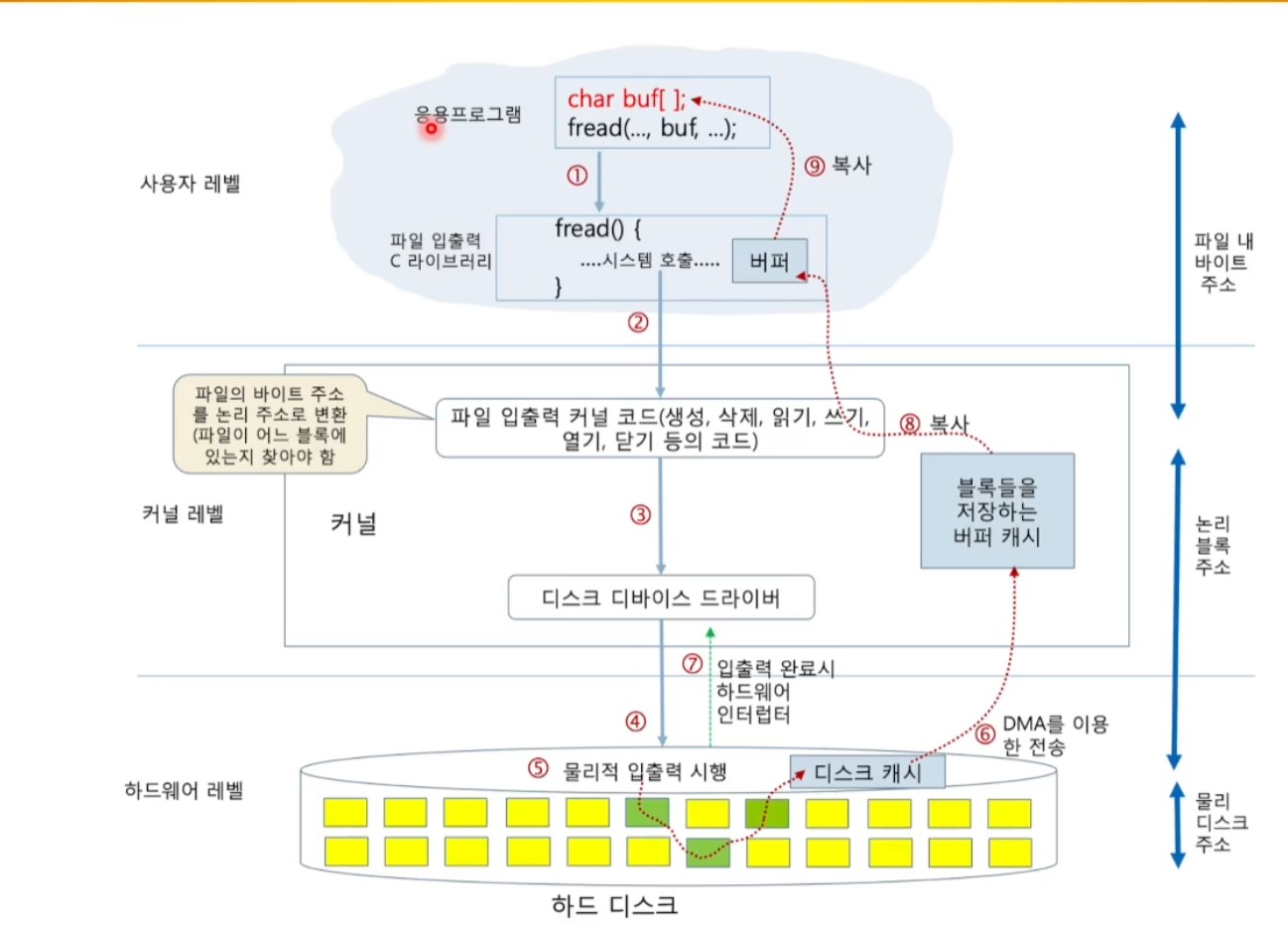
<보조 저장 장치 접근의 특징>
- 각 계층의 관점과 역할이 잘 구분됨
- OS는 app이 저장장치의 물리적 특성(종류, 구조, 위치 등)과 무관하게 입출력 지원 가능
- 데이터는 여러 단계의 버퍼를 통해 전달됨
- 시간 오버헤드 발생 가능
- 동일 내용 반복 접근시 캐시 효과
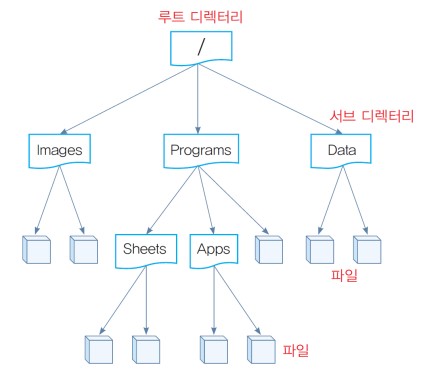
<파일 시스템 구조>
- 트리 형태의 계층 구조로 구성
- 파일
- 디렉터리
<파일 시스템(File System)>
<디렉터리(directory)>
- 자신에게 포함된(논리적으로) 파일에 대한 목록을 담고 있는 특수 파일
- 단, 파일 블록들이 저장된 디스크 상의 위치는 FAT/i-node라는 특별한 곳에 따로 저장
<파일시스템 관리 위한 메타 정보>
- 파일 시스템 전체에 대한 메타 정보
- 파일 시스템의 전체 크기
- 파일 시스템의 현재 사용 크기
- 파일 시스템의 빈 크기 및 빈 블록 목록
- 각 파일에 대한 메타 정보
- 파일 이름, 파일 크기
- 파일 생성, 수정, 최근 접근 시각
- 생성 사용자 정보 및 접근 권한
<파일 시스템의 종류>
- FAT(File Allocation Table) 파일 시스템
- MS-DOS에서 사용. 최근에도 사용되고 있음
- UFS(Unix File System)
- Unix에서 사용
- ext2, ext3, ext4
- 리눅스에서 사용
- HFS(Hierarchical File System), AFS
- Mac 운영체제에서 사용
- NTFS(New Technology File System)
- FAT 개선, 리눅스에서도 지원됨
<파일 시스템 구현 이슈>
- 디스크 장치에 비어 있는 블록들의 리스트를 어떻게 관리할 것인가?
- 파일 블록들을 디스크의 어느 영역에 어떻게 분산 배치할 것인가?
- 파일 블록들이 저장된 디스크 내 위치들을 어떻게 관리할 것인가?
<Unix 파일 시스템의 구조>
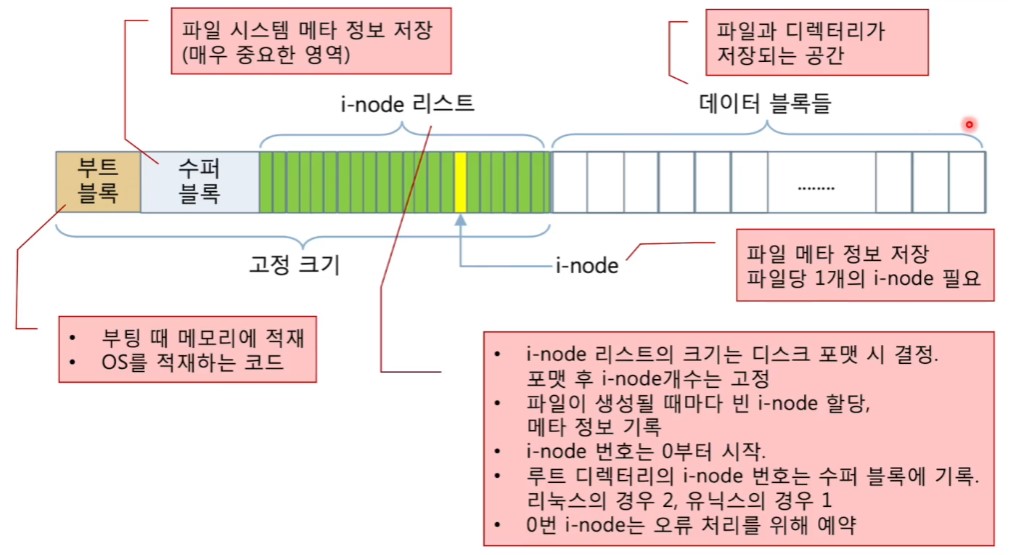
*부트블록
- 부팅 때 메모리에 적재
- OS를 적재하는 코드
*수퍼 블록
- 파일 시스템 마테 정보 저장(매우 중요한 영역)
*i-node
- 파일 메타 정보 저장
- 파일당 1개의 i-node 필요
- ex) 파일 타입과 접근 권한
파일 소유자 ID
파일 그룹 ID(파일 접근 권한을 가진 그룹ID)
파일 크기
마지막 파일 접근 시각
마지막 파일 수정 시각
마지막 i-node 수정 시작
파일 블록들에 대한 인덱스 등
*i-node 리스트(i-node들이 나열된 일련의 목록)
- i-node 리스트의 크기는 디스크 포맷 시 결정, 포맷 후 i-node의 개수는 고정
- 파일이 생성될 때마다 빈 i-node 할당, 메타 정보 기록
- i-node의 번호는 0부터 시작
- 루트 디렉터리의 i-node 번호는 수퍼 블록에 기록, 리눅스의 경우2, 유닉스의 경우1
- 0번 i-node는 오류 처리를 위해 예약
*데이터 블록들
- 파일과 디렉터리가 저장되는 공간
<디렉터리 블록>
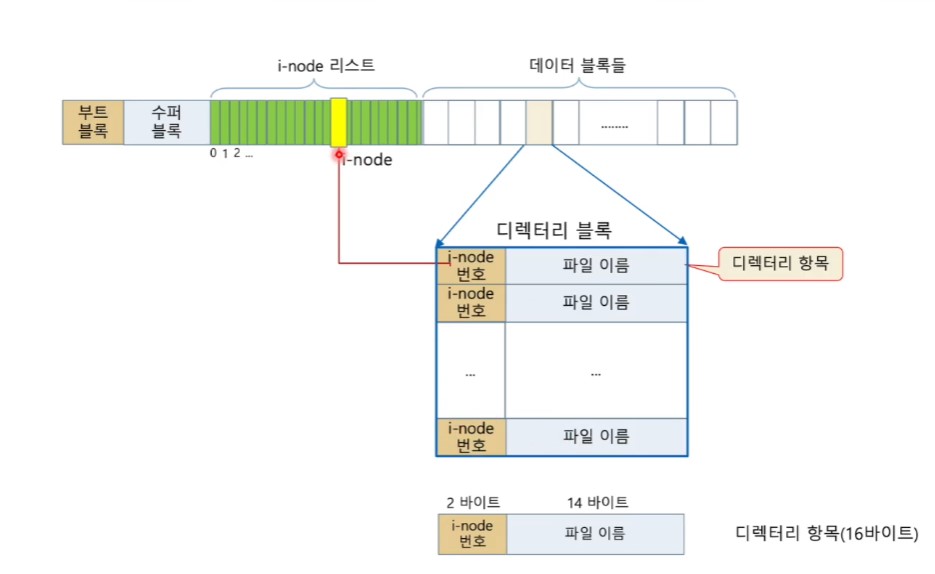
<수퍼 블럭(super block)>
- 파일 시스템 유지 관리를 위해 중요한 정보인 파일 시스템 메타 정보 기록
- 파일 시스템의 크기와 상태 정보
- 자유 블록들의 리스트와 그 수
- inode 리스트의 크기
- 자유 inode들의 리스트와 그 수
- 자유 inode 리스트에서 다음 자유 inode 인덱스
- 루트 디렉터리의 i-node 번호
- 수퍼 블록이 갱신된 최근 시간
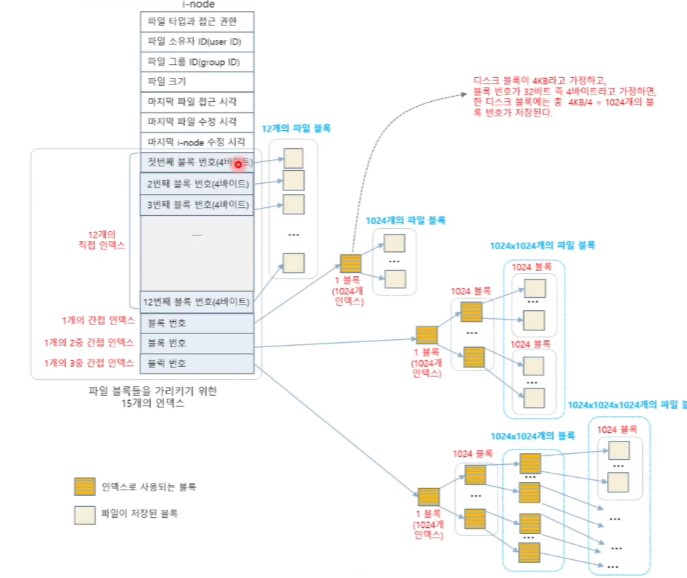
<파일 블록 할당(File Allocation)_Unix>
- i-node의 15개 인덱스로 블록들의 위치 저장
- 12개의 직접 인덱스
- 12개의 파일 블록 번호 : 12 x 4KB = 48KB
- 1개의 간접 인덱스
- 한 블록이 4KB이고, 블록 번호가 32비트(4바이트) 일 때
- 4KB/4B = 1024 블록
- 파일 크기 : 1024 x 4KB = 4 x (2^20B) = 4MB
- 1개의 2중 간접 인덱스
- 1024 x 1024 블록
- 파일 크기 : 1024 x 1024 x 4KB = 4 x 2^30 바이트 = 4GB
- 1개의 3중 간접 인덱스
- 1024 x 1024 x 1024 블록
- 파일 크기 : 1024 x 1024 x 1024 x 4KB = 4 x 2^40 바이트 = 4TB
*바이트(byte) : 1byte = 8bit
킬로 바이트(KB) = 1KB = 1024byte, 1KB = 1024 x 8
메가 바이트(MB) = 1MB = 1024KB
기가 바이트(GB) = 1GB = 1024MB
테라 바이트(TB) = 1TB = 1024GB
<파일 블록의 할당>
</usr/source/main.c>
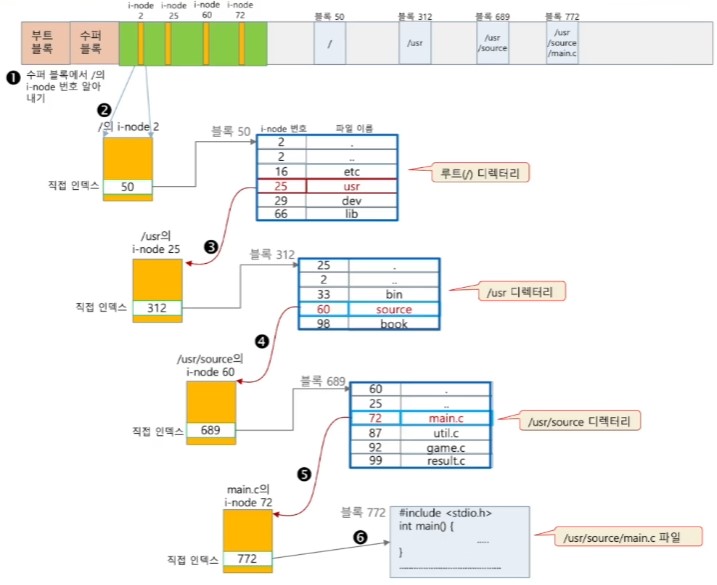
<파일의 i-node 찾기>
- 파일을 읽고 쓰기 위해 파일 블록들의 위치 파악 필요
- 파일블록들의 위치는 i-node의 15개 인덱스로 유지
- ex) /urs/source/main.c
1. 수퍼 블록에서 루트(/)의 i-node 번호 알아내기
2. 루브 디렉터리(/)의 i-node 읽기
3. 루트 디렉터리에서 /usr의 i-node 알아내기
4. /usr 디렉터리를 읽고 /usr/source 파일의 i-node 번호 알아내기
5. /usr/source 디렉터리 읽고 /usr/source/main.c 파일의 i-node 번호 알아내기
6. /usr/source/main.c 파일 읽기
<파일 입출력 연산>
- 커널의 파일 시스템은 파일 입출력을 위한 시스템 호출 함수 제공
- open()
- read()
- write()
- close()
- chmod()
- create()
- mount()
- unmount()
- 등
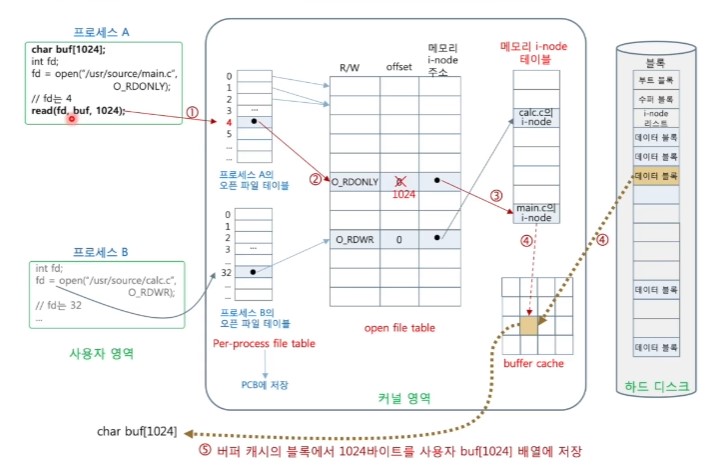
<파일 열기 : open()>
- 왜 파일을 열어야 하나?
- 파일이 존재하는지 확인
- 파일에 대한 현재 프로세스의 접근 권한 확인
- 파일을 읽고 쓰기 위한 커널 내 자료 구조 형성
- 메모리 i-node 테이블
- 오픈 파일 테이블
- 프로세스별 오픈 파일 테이블
- 버퍼 캐시
<파일 열기 후 형성되는 커널 자료 구조>
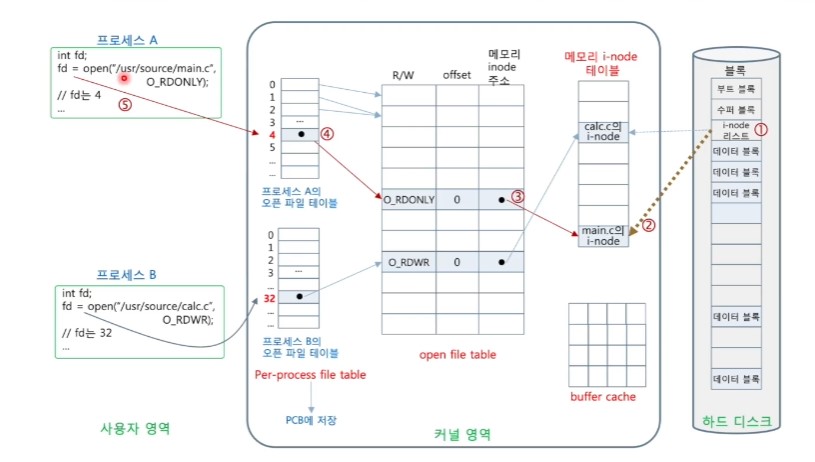
<파일 입출력을 위한 커널 내 자료 구조(1/2)>
- 메모리 i-node 테이블
- 현재 열린 파일의 디스크 상의 i-node를 읽어 메모리 내에 저장한 테이블
- 파일 블록 위치 등 i-node를 액세스할 때 빠른 처리를 위해 메모리에 적재
- 오픈 파일 테이블(open file table)
- 시스템 내의 모든 열린 파일들에 대한 정보 기록
- 파일 열기 모드, 파일 옵셋(file offset), 메모리에 적재된 inode 주소
- 모드 프로세스에 의해 공유
*오프셋(offset)
- 배열이나 자료구조 오브젝트 내의 오프셋(offset)은 일반적으로 동일 프로젝트 안에서 오브젝트 처음부터 주어진 요소나 지점까지의 변위차를 나타내는 정수형이다
이를테면, 문자 A의 배열이 'abcdef'를 포함한다면 'c'문자는 A시작점에서 2의 오프셋을 지닌다고 할 수 있다
- ex) 문자 C는 100번지의 주소를 가리키고 있다. 'C+7' 위와 같은 수식이 있을 때, '7'이 오프셋(offset)을 의미한다
또한, 이 수식의 결과는 107번지를 의미한다. 오프셋을 이용하여 주소를 나타내는 '상대주소 지정방식' 이라고도 표현한다
<파일 입출력을 위한 커널 내 자료 구조(2/2)>
- 프로세스별 오픈 파일 테이블
- 현재 프로세스가 연 파일에 대해 오픈 파일 테이블 항목 주소를 가짐
- 프로세스 마다 하나씩 있음(스레드간 공유)
- 프로세스가 파일을 열 때마다 항목 할당, 닫으면 소멸시킴
- 각 항목 번호는 open()의 반환값(파일 디스크립터)
- 운영체제는 프로세스를 실행시킬 때 표준 입력, 표준 출력, 표준 오류용으로 3개의 항목을 열어놓음, 각각 0,1,2 항목
- 이 테이블은 PCB에 저장
- 버퍼 캐시(buffer cache)
- 읽혀지거나 쓰여지는 파일 블록들이 일시적으로 저장
- 디스크 블록 번호로만 관리
<파일 열기 과정>
1. 파일 이름으로 i-node 번호를 알아내기
2. 디스크 i-node를 커널 메모리의 i-node 테이블에 적재
3. 오픈 파일 테이블에 새 항목 만들기
4. 프로세스별 오픈 파일 테이블에 새 항목 만들기
5. open()은 프로세스별 오픈 파일 테이블 항목 번호 반환
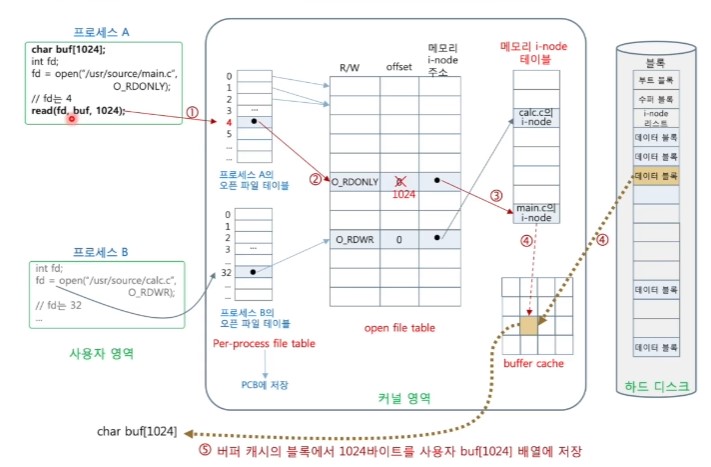
<파일 읽기 과정>
1. read()는 fd번의 프로세스별 오픈 파일 테이블 참조
2. 오픈 파일 테이블 참조
- R 모드(읽기 허용)가 아닌 경우 오류로 리턴
3. i-node 참조
- i-node에서 파일 블록들의 리스트 확보
- 해당 테이블 항목에서 offset 확인 후 파일 블록 번호로 변환
4. 해당 블록이 버퍼 캐시에 있는 지 확인
- 해당 블록이 버퍼 캐시에 없으면, 버퍼 캐시를 할당받고 디스크에서 버퍼 캐시로 읽기
- 할당 받은 버퍼 캐시가 dirty이면 버퍼 캐시에 있는 블록을 디스크에 쓰기
5. 버퍼 캐시로부터 사용자 영역으로 블록 복사
<파일 쓰기 과정>
1. write()는 fd번호의 프로세스별 파일 테이블을 참조
2. 파일 테이블 참조
- W 모드(쓰기 허용)가 아니면 오류로 리턴
3. i-node 참조
- i-node에서 파일 블록들의 리스트 확보
- 파일 테이블 항목에서 offset 확인 후 파일 블록 번호로 변환
4. 해당 블록이 버퍼 캐시에 있는 지 확인
- 해당 블록이 버퍼 캐시에 없으면, 버퍼 캐시를 할당 받고 디스크 블록을 버퍼 캐시로 읽어 들이기
5. 사용자 공간의 버퍼에서 버퍼 캐시로 쓰기
6. 추후 버퍼 캐시가 교체되거나 플러시 될 때, 버퍼 캐시의 내용이 저장 장치에 기록
*버퍼 플러시(buffer flush) : 버퍼가 꽉 차지 않았어도 즉시 출력을 하여 버퍼를 비워버리는 것
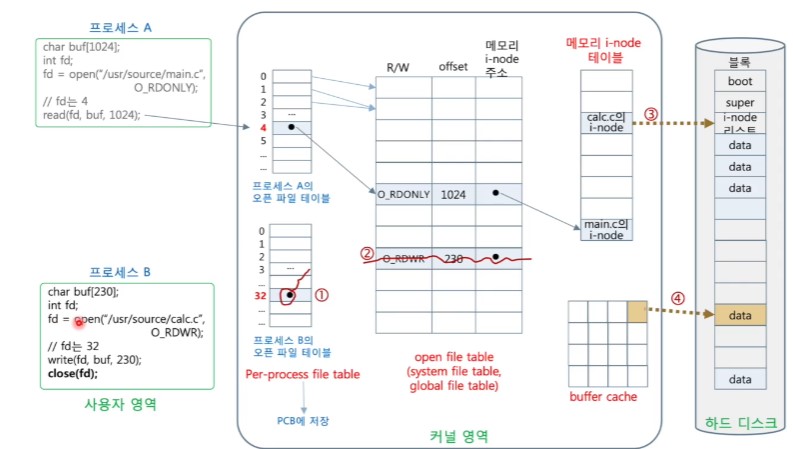
<파일 닫기 : close()>
- open()에서 구성한 자료 구조를 해제 하는 괒어
1. 프로세스 별 파일 테이블로부터 오픈 파일 테이블 항목을 찾음
2. 버퍼 캐시에 있는 이 파일의 블록들이 수정되었거나 새로 만든 블록인 경우 디스크에 기록
- 캐시 내용은 남겨둠
3. 메모리 i-node의 사용 해제
4. 오픈 파일 테이블의 항목을 (지우고) 반환하기
5. 프로세스의 오픈 파일 테이블 항목에 기록된 내용 삭제
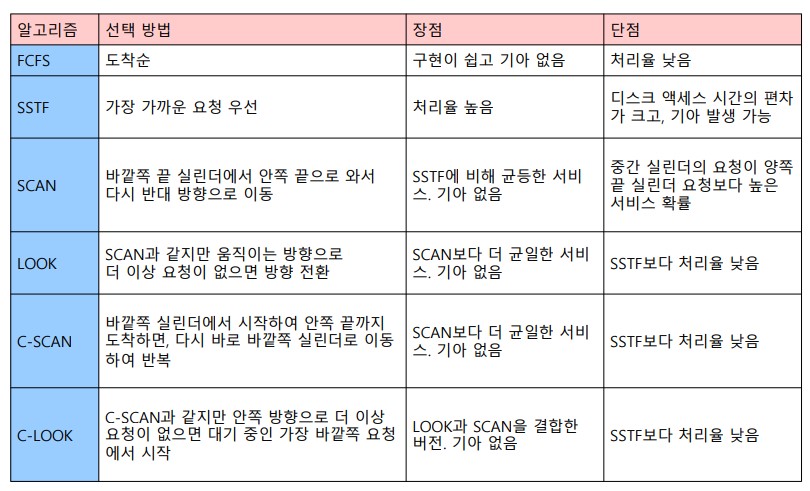
<디스크 스케줄링>
- 프로세스들의 디스크 I/O 요청들이 큐에 대기, 이 중 하나를 선택해 처리
- 효율적인 디스크 접근 스케줄링 필요
- 큐에 저장된 입출력 오청들의 목표 실린더 위치 고려
- 평균 탐색 시간/평균 디스크 접근 시간 최소화
<디스크 스케줄링 알고리즘>
- 디스크 헤드 이동을 최소화
- FCFS
- SSTF(Shortest Seek Time First)
- SCAN
- C-SCAN(Circular SCAN)
- LOOK
- C-LOOK(Circular LOOK)
- 평가 기준
- 평균 탐색 거리
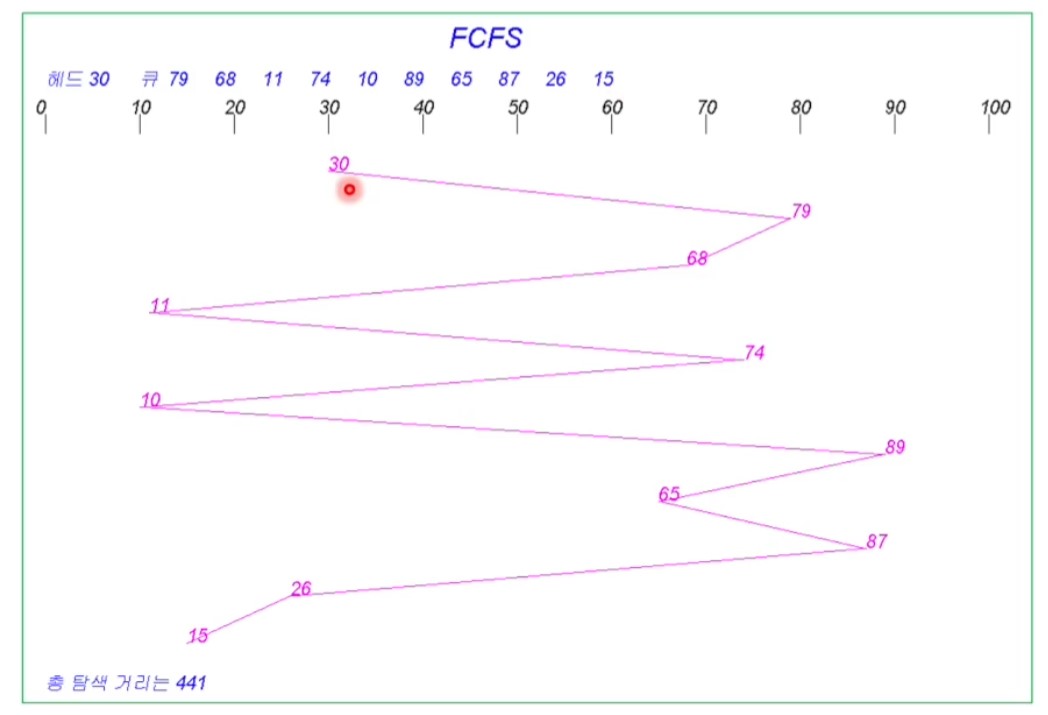
<FCFS(First-Come-First-Serve) Scheduling>
- 디스크 큐 검색 불필요. 구현이 쉽고 기아 없음
- 일반적으로 빠른 서비스를 제공하지 못함
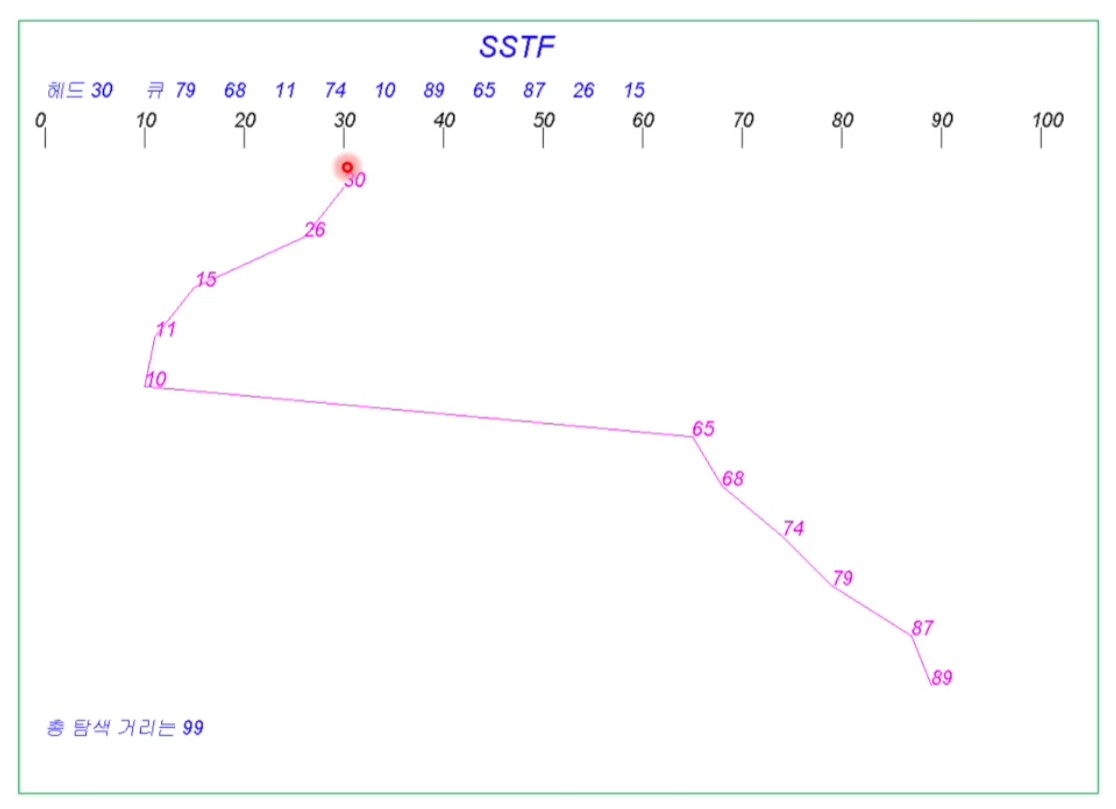
<SSTF(Shortest Seek Time First) Scheduling)>
- 최소 탐색 시간 우선
- 현재 디스크 헤드 위치에서 가장 가까운 요청을 먼저 처리
- 현재 헤더에서 멀리 있는 요청은 기아 상태 발생 가능
- seek time이 최소이긴 하지만 가장 최적이라고 할 수는 없음
- 대화식 처리 시스템의 경우 불확실한 예측 가능시간 때문에 부적당
- 바깥쪽 실린더에 대한 요청들은 오래 대기할 수 있음 -> 응답 편차가 큼
- 배치 처리 시스템의 경우 적용 가능
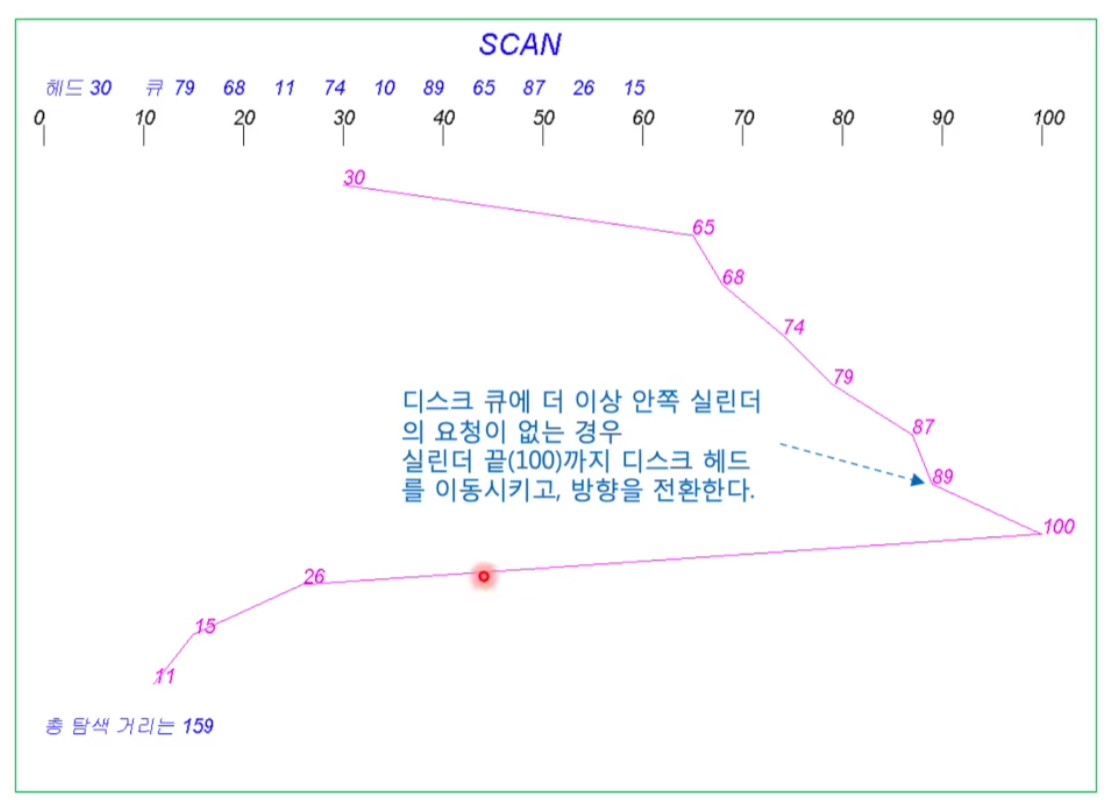
<SCAN Scheduling>
- =엘리베이터 알고리즘(Elevator algorithm)
- 디스크 헤드가 한쪽 끝에서 다른 끝으로 이동해가며 요청을 처리
- 끝에 도달하면 반대 방향으로 이동
- 새 요청이,
- 헤드 진행 방향에 생기면 즉시 처리
- 헤드 진행 방향 뒤에 생기면 되돌아 올 때 처리
- SSTF에 비해 균등한 입출력 서비스
- 단, 양끝쪽 실린더 요청들은 중간보다 선택될 확률이 낮음
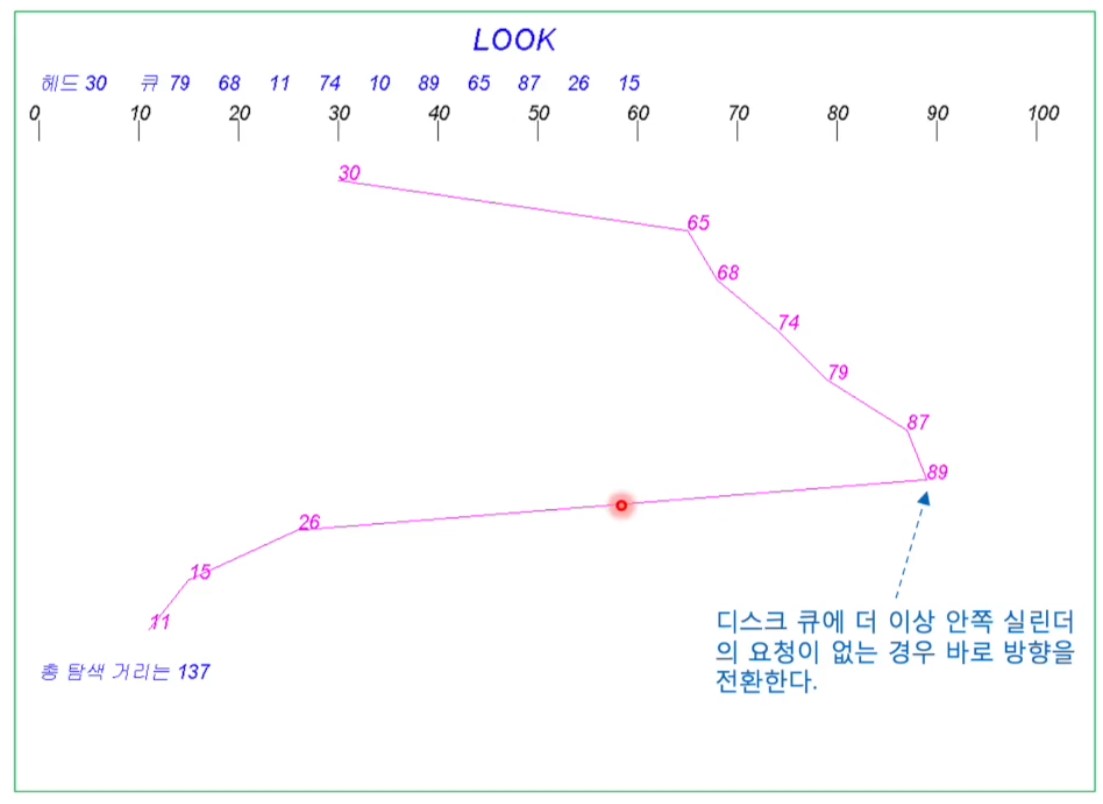
<Look Scheduling>
- 진행 방향에 요청이 없으면 바로 방향전환
- SCAN의 변형
- 한쪽 방향 마지막 요청에 도달하면 반대로 이동
- 맨 끝 실린더로 이동하면 SCAN의 단점 보완
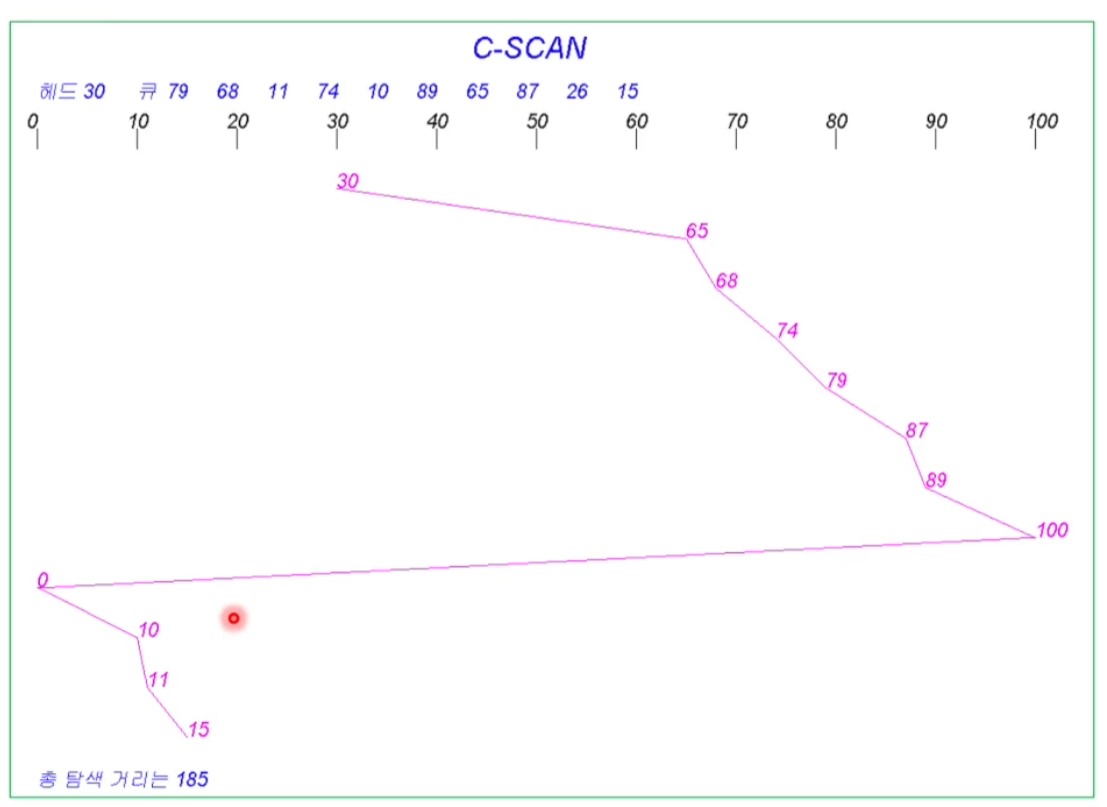
<C-SCAN(Circular-SCAN) Scheduling>
- 순환 스캔
- SCAN보다 좀 더 균등한 요청 시간을 제공
- 디스크 헤드가 한쪽 끝에서 다른 끝으로 이동해가며 요청을 처리
- 끝에 도달하면 즉시 시작 위치로 돌아감
- 방금 처리가 끝난쪽보다는 반대쪽 끝에 처리될 요청들이 대기중일 확률이 높으므로
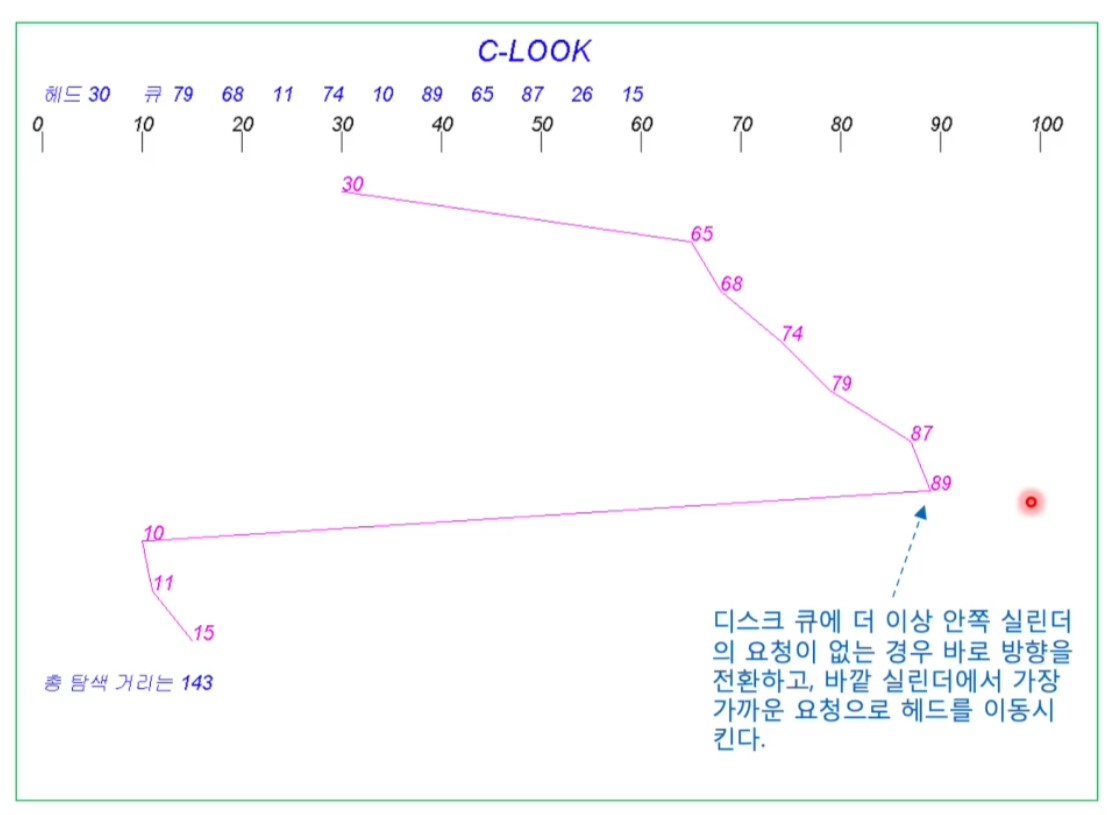
<C-LOOK Scheduling>
- 진행 방향에 요청이 없으면 바로 방향전환
- C-SCAN의 변형
- 한쪽 방향 마지막 요청에 도달하면, 다른쪽 끝방향 마지막 요청으로 이동
<디스크 스케줄링 알고리즘 특성 비교>
<Disk Scheduling Algorith의 선택>
- 성능은 요청의 형태와 회수에 좌우됨
- 디스크 요청은 파일 할당에 영향 받음
- 연속 할당된 파일 <=> 산재되어 할당된 파일
- 디렉터리와 인덱스 블록의 위치가 중요
- 빈번한 접근이 발생하기에
- 일반적으로 SSTF나 LOOK이 무난함
- SCAN/C-SCAN은 디스크를 많이 사용하는 시스템에 적합
<Disk Scheduling의 책임>
- OS와 분리된 모듈로 구현되어야 더 나은 알고리즘으로 대체될 수 있다
- 디스크 I/O 성능만 본다면, 스케줄링에 관한 책임을 하드웨어에게 일임이 바람직
- 하지만, 성능 이외의 몇가지 고려사항 때문에 OS가 간섭해야 한다
- I/O 작업 간의 우선순위
- 페이징 관련 입출력 > 일반 입출력
- 디렉터리 정보 갱신 > 파일 내용 입출력


